Why Does Claude Code Work So Well on Non‑Coding Tasks?
Why Does Claude Code Work So Well on Non‑Coding Tasks?
A Look at the Generalization of Agent Scaffolding
Cover:Claude Code Official Homepage
If you’re a developer, you’ve probably heard of Claude Code, OpenCode, or earlier systems like SWE‑Agent. These tools were originally created to solve software engineering problems — fixing bugs, writing code, running tests.
But there’s an interesting phenomenon: they don’t just code. They often perform surprisingly well on tasks that don’t look like “coding tasks” at all.
For example, you can ask Claude Code to organize files on your desktop, bulk‑rename a folder of photos, or automatically fill out a form — and it usually does a decent job.
A big part of that comes from the underlying models. But there’s another, often overlooked, factor: agent scaffolding.
This article is about that.
First, Clear Up a Few Confusing Terms
Before we talk about agent scaffolding, we need to disentangle a few concepts that non‑specialists often mix up.
LLM (Large Language Model)
You can think of an LLM as the “engine” or “brain” at the very bottom. Examples: GPT‑5, Claude 4.5 Sonnet, DeepSeek‑V3. You feed it a sequence of tokens (usually text), and it outputs another sequence of tokens (classical LLM outputs one token at a time) — that’s it.
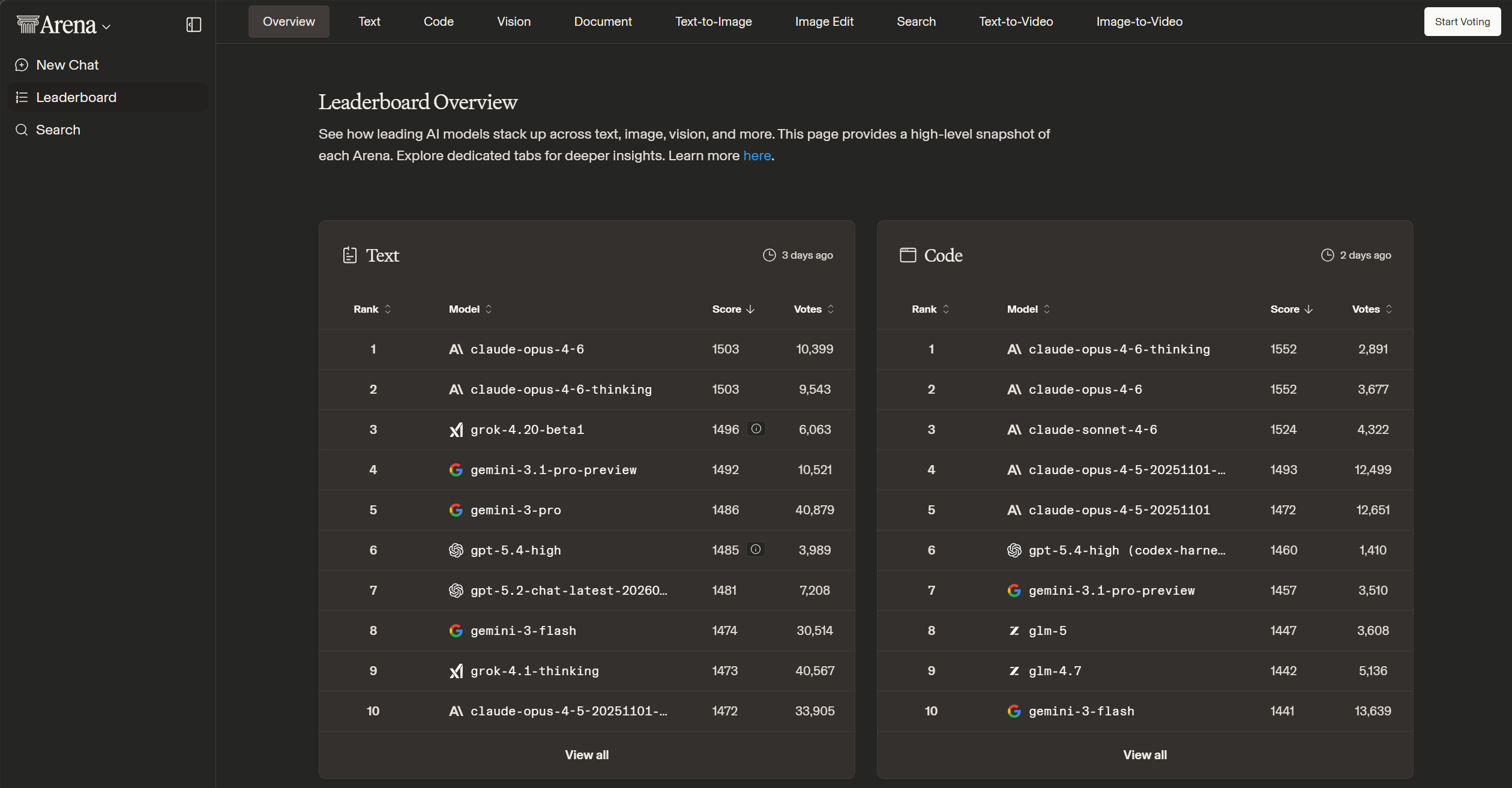 A famous leaderboard for LLMs
From:LM Arena
A famous leaderboard for LLMs
From:LM Arena
An LLM:
- does not click buttons,
- does not read files by itself,
- does not access the network on its own.
It’s a powerful sequence generator, not an app. It has no idea which product it’s embedded in or who is using it; it just maps input to output.
LLM Agent
An LLM agent is what you get when you wrap an LLM with a “body” and “senses.” The LLM is still the brain, but you attach “hands and eyes” around it — tools for:
- reading and writing files,
- executing shell commands,
- calling HTTP APIs,
- operating a browser, and so on.
Roughly speaking, an agent:
- translates a natural‑language request into a sequence of actions, and
- in each step, uses the LLM to think, then uses tools to act.
Claude Code is a classic example of an LLM agent: internally it has multiple sub‑agents (read code, edit code, run tests, etc.), all powered by one or more LLMs, but to the user it looks like “an assistant that can actually work on the codebase.”
 Another famous leaderboard, but this time it focuses on LLM agents, focusing on terminal commands.
From:terminal-bench
Another famous leaderboard, but this time it focuses on LLM agents, focusing on terminal commands.
From:terminal-bench
LLM Application
An LLM application sits one layer above agents — it’s the product you actually use. It isn’t just an agent; it’s a full system that includes:
- front‑end interfaces (web UI, desktop app, IDE plugin, mobile app),
- back‑end services (auth, logging, billing, permissions, org management, etc.),
- one or more LLMs / LLM agents as its internal engines.
For example:
- ChatGPT is an LLM‑based application. Behind the scenes it likely orchestrates multiple models, multiple agents, and multiple tool systems, but the user only sees a single product.
- The AI coding tool you’re using inside your IDE is also an LLM application — it just happens to live inside your editor.
In other words:
- “LLM” is the chip,
- “LLM agent” is the machine built around that chip,
- “LLM application” is taking that machine, packaging it into a product, and putting it in users’ hands.
Company , Model Provider and Product
Another common confusion is between company names, model names, and product names:
- Anthropic is a company.
- It provides the Claude family of models (in this context, it’s a model provider).
- It also provides products like Claude Chat and Claude Code (in this context, it’s an application provider).
- OpenAI is similar:
- GPT‑4, GPT‑4.1, o3, etc. are models.
- ChatGPT, the ChatGPT desktop app, and various enterprise offerings are applications.
- On top of that, the company runs an API platform, plugins, and more.
Being explicit about which layer you’re talking about helps a lot. When you say “I want to use Claude,” do you mean:
- the Claude model,
- the Claude chat product, or
- the Claude Code agent?
Being precise saves a lot of confusion when you evaluate tools or architect systems.
A Brief History of Agent Scaffolding: From Prompts to Agents
To understand why today’s agent scaffolds generalize so well, it helps to look at how they evolved.
1. Prompt Engineering: The First Wave
Early LLM “applications” were mostly prompt engineering: write a good prompt and get a good answer.
You might say: “Please write a Python implementation of quicksort.” The model outputs a code snippet.
This approach is simple and often effective, but it has a fatal limitation: the model is “lazy.”
If you ask it to write code, it only writes code. If you ask for a summary, it only summarizes. It won’t:
- go look up external information,
- verify its own answers, or
- proactively ask clarifying questions when your instructions are ambiguous.
2. Chain‑of‑Thought: Teaching Models to Think
In 2022, Google researchers introduced Chain‑of‑Thought (CoT) prompting[1]. The core idea is simple: have the model write out its reasoning steps instead of directly outputting the final answer.
Example:
-
Without CoT:
John has 5 apples, Stephen gives him 3 more. How many apples does he have now?” → Model answers “8.” -
With CoT:
Model writes “5 + 3 = 8, so he has 8 apples.”
This looks minor but is actually a big deal. CoT pushes the model to “think step‑by‑step,” significantly improving performance on math and logic tasks[1].
 From:Kojima et al., Large Language Models are Zero-Shot Reasoners
From:Kojima et al., Large Language Models are Zero-Shot Reasoners
But CoT still only addresses thinking, not doing. The model can reason in its “head,” but it still can’t:
- verify its answers by running code,
- fetch fresh information from the internet, or
- interact with external systems.
3. ReAct: Reasoning + Acting
In 2022, Yao et al. published the ReAct paper[2], with a key insight: it’s not enough for the model to think — it also has to act.
ReAct’s core loop is “Thought → Action → Observation”:
- Thought: Analyze the situation and plan the next step.
- Action: Execute an action, such as searching, calling an API, or reading a file.
- Observation: Take in the result and update the internal state.
- Repeat until the task is done.
As one researcher put it: “CoT gave models the ability to reason, tool calling gave them the ability to act, but we lacked a mechanism to combine the two. ReAct fills in that missing piece.”[3]
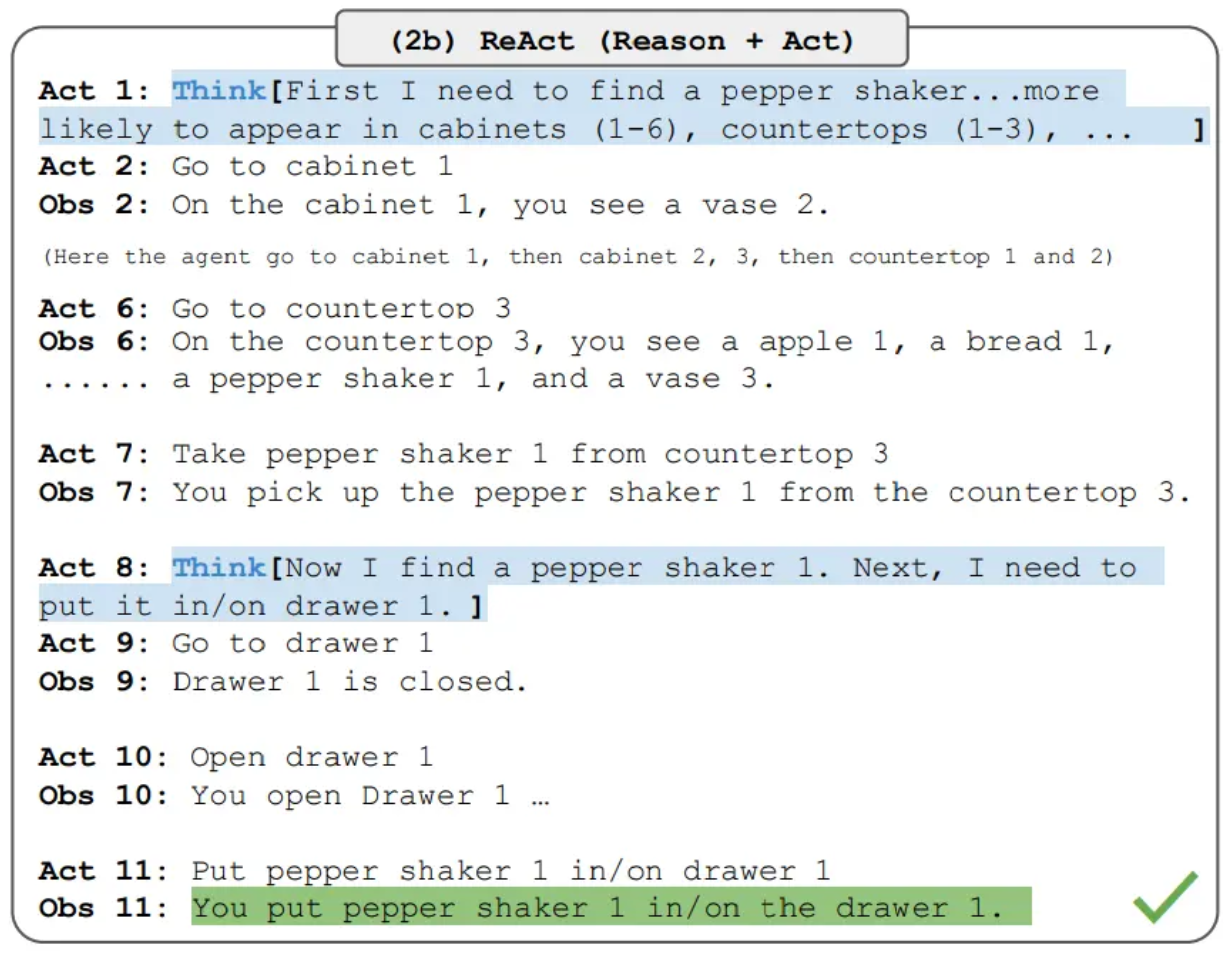 From:Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models
From:Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models
Interestingly, ReAct also helps reduce hallucination. On HotpotQA, CoT alone produced incorrect statements in over half of the cases, while ReAct brought that close to zero[3].
4. SWE‑Agent: Specialization for Code
Building on ReAct, domain‑specific agents for coding started to appear. SWE‑Agent is a canonical example[4].
Its key innovation is the CodeAct Agent design:
- a File agent that reads and understands code files,
- an Edit agent that modifies code,
- a bash agent that executes shell commands,
- optionally a Browser agent that handles web tasks.
Each sub‑agent has a clear responsibility, and a central scheduler coordinates their work. This architecture allows SWE‑Agent to handle complex, multi‑step software engineering tasks.
This design philosophy later spread more broadly and evolved into the terminal‑native agents we see today.
5. Claude Code, OpenCode: The Rise of Terminal‑Native Agents
By 2024–2025, terminal‑native agents became a major trend.
- Claude Code is Anthropic’s terminal‑native AI coding assistant. It supports two core modes[5]:
- Terminal mode for interactive development;
- Gateway mode for 24/7 operation, listening to sources like WhatsApp, Telegram, Slack, etc.
A key innovation is its sub‑agent architecture. Claude Code can run multiple parallel agents, each with its own context window, model choice, tool access, and permissions. A dedicated Explore agent (running a smaller model like Claude Haiku) is used for code search, while more complex work is routed to Sonnet or Opus[5].
- OpenCode is another notable project. As an open‑source coding agent, it has amassed well over 100K GitHub stars and is used by millions of developers[6]. Its core idea is “provider‑agnostic”: it supports 70+ model providers, including Claude, GPT, Gemini, and many local models[6].
These systems are no longer just “good prompts” — they are full scaffolds for autonomous coding agents.
How Claude Code‑Style Agents Actually Work
Claude Code is closed‑source, so we can’t inspect its implementation directly. But we can extrapolate from its “close relatives”: open‑source systems like SWE‑Agent and OpenDev[4][7].
Core Workflow
Take SWE‑Agent as an example. Its workflow looks roughly like this[4]:
-
Understand the task
The agent receives a natural‑language instruction (e.g., “help me fix this bug”) and decides which steps are needed. -
Plan the path
It creates a plan: which files to read, which ones to edit, and how to verify the fix. - Execute actions
It starts acting according to the plan. It may:- read file contents,
- search the codebase,
- edit code,
- run commands,
- execute tests.
-
Observe feedback
After each action, it captures outputs (command logs, test results, etc.) and updates its internal understanding. - Iterate and refine
If the current plan isn’t working, it adjusts the strategy and tries again.
Key Components
A full agent scaffold typically includes the following components[7]:
- System prompt: defines the agent’s role, boundaries, and behavioral rules.
- Tool schemas: describe available tools and how to call them.
- Sub‑agent registry: manages multiple sub‑agents, their configs, and permissions.
- Context manager: tracks conversation history, file contents, and execution state.
- Execution harness: dispatches tasks, routes tool calls, and enforces safety.
This is why one Morph analyst could say: “We tested 15 AI coding agents and found that the scaffold matters more than the model. Augment, Cursor, and Claude Code all use Opus 4.5, but their SWE‑bench scores differ by over a dozen problems.”[8]
Why Does Agent Scaffolding Generalize So Well?
Looking at the workflow above, you might think: “That’s it? It’s not that fancy.”
And you’d be right — there are no magical tricks, just a clean design.
So here’s the core question of this article:
Why do scaffolds designed for coding tasks perform so well on many non‑coding tasks?
I think there are a few key reasons.
1. ReAct Is a Domain‑Agnostic Pattern
First, and most fundamentally, ReAct is a general problem‑solving framework, not a coding‑only trick.
The loop “Thought → Action → Observation” works for almost any task:
- understand the task,
- plan,
- act,
- observe,
- refine.
Whether you’re:
- writing code,
- organizing files, or
- researching on the web and compiling a report,
the core loop looks the same. That’s why ReAct works across tasks from HotpotQA (knowledge QA) to ALFWorld (text‑based environments)[2].
2. A Rich Tool Ecosystem: MCP and Skills
Second, the tool ecosystem dramatically extends what agents can do.
MCP (Model Context Protocol), proposed by Anthropic, is an open standard for connecting agents to external tools and data sources[9]. As of early 2026, MCP has:
- over 10,000 active servers, and
- more than 97 million monthly SDK downloads across major languages[9].
Practically, this means agents can now:
- integrate with tools like GitHub, Slack, and Linear,
- operate databases and call arbitrary APIs,
- send emails and manage calendars,
- even control smart‑home devices.
Skills add another layer. In Claude Code and OpenCode, Skills are reusable workflows[10]. For example, you can define a “send weekly report” Skill that chains together:
- reading project progress,
- generating a report,
- emailing it to a mailing list.
With MCP and Skills combined, the scaffold essentially gains an extensible toolbox. It’s no longer constrained to code tasks; it can reach into almost any system you expose.
3. Most Problems Can Be Reframed as Code Problems
The third reason sounds counterintuitive but is crucial:
many tasks that don’t look like coding problems can, in fact, be turned into coding problems.
Consider a few examples.
Example 1: Organizing Desktop Files
You ask the agent to sort your desktop files into folders based on file type. That sounds like a “file management” task, but from a coding perspective it’s just:
- using Python’s
osandshutilto list the desktop directory, create target folders, and move files, - using regex to group files by naming patterns (dates, project names, version tags),
- optionally using
PILorexifreadto read EXIF data and classify images by capture date or device.
In other words, the task is:
“read directory → compute grouping rules → move/rename files.”
The agent’s job is to understand your natural‑language request and then write and execute that script — instead of dragging icons one by one.
Example 2: Bulk‑Renaming Photos
You ask the agent to rename a batch of photos by date. This looks like an image task, but you can model it as:
- using
exifreadto parse each photo’s EXIF metadata, - using
datetimeto format timestamps into names like2026-02-23_trip_001.jpg, - using
os.renameto apply the new names in bulk.
That’s just a pipeline of “parse metadata → generate new names → apply renames.” The agent is simply writing and running a small renaming tool for you.
Example 3: Automatically Filling Web Forms
You ask the agent to take data from an Excel sheet and fill it into a web form. It sounds like a “GUI automation” task, but if you allow HTTP/browser automation, it’s really:
- using
openpyxlorpandasto read the structured data, - mapping each column to form fields or a JSON payload,
- using
requeststo submit directly, or using Selenium/Playwright to drive the browser.
From a code standpoint, it’s a standard ETL job:
“read structured data → map fields → send requests.”
Example 4: Generating Weekly Reports
People often ask agents to “write a weekly report,” which feels like a pure writing task. But if you decompose it, you get:
- a script that collects events from Git commits, issues/PRs, calendar entries, and chat logs (Slack/Teams/Feishu),
- logic to aggregate and filter them (by project, by priority, etc.),
- a final LLM call that turns structured bullet points into a readable summary.
In this pipeline, the LLM handles wording and structure. The heavy lifting of data gathering and aggregation can be done entirely in code.
Example 5: Cleaning a Messy CSV
You ask the agent to “clean up” a dirty CSV file. It sounds like data analysis, but it’s naturally modeled as:
- using
pandasto load the CSV, - defining rules: drop empty rows, fill missing values, standardize timestamp formats, normalize categorical values (e.g.,
Y/Yes/True→True), - detecting and flagging outliers for review using statistical methods.
The output is a cleaned CSV plus a reusable cleaning script.
The pattern should be clear: code is the native language of automation.
File operations, data processing, network requests, system admin — all can be expressed as code.
So when you see an agent doing something that “doesn’t look like coding,” chances are that under the hood it’s quietly writing and running scripts.
4. Stronger Base Models Supercharge the Same Scaffold
We also shouldn’t understate the contribution of the underlying models.
2025 was a breakout year for LLM capabilities. OpenAI’s o1/o3 series, Anthropic’s Claude 4 family, and Google’s Gemini 2.5 all demonstrated impressive reasoning and planning abilities[11].
More importantly, these models are increasingly general‑purpose. A well‑trained model can:
- understand complex natural‑language instructions,
- perform multi‑step reasoning,
- call various tools,
- learn from feedback and adjust.
This is like upgrading the “brain” inside the same scaffold. With the same architecture and tools, swapping in a stronger model can make the system feel like an entirely different product.
Will Agent Scaffolding See a “Revolution”?
After all this, you might ask: will agent scaffolds themselves undergo a revolutionary change?
I’d say I’m cautiously optimistic.
Likely Directions
-
Richer multimodal integration
Future agents will likely integrate vision, audio, and other signals more seamlessly, handling much more complex perception. -
More autonomous planning
Today’s agents are still largely reactive: you give a task, they respond. Future agents may plan long‑term goals and execute them proactively. -
Better memory systems
Current agents often “forget” context over long sessions. We can expect stronger memory mechanisms that maintain coherence over days or weeks.
Persistent Challenges
At the same time, there are fundamental challenges:
-
Execution uncertainty
The real world is messy. Actions may not have predictable outcomes. Getting agents to handle all the edge cases robustly is hard. -
Security and permissions
Giving agents broad execution rights is inherently risky. Balancing capability and safety is an ongoing challenge. -
Evaluation
How do we rigorously evaluate an agent’s capability? Existing benchmarks like SWE‑bench and Terminal‑Bench are useful but incomplete[8].
Summary
Back to the original question: why does Claude Code perform so well on many non‑coding tasks?
By now, the answer should be clear:
- ReAct is a general reasoning‑and‑acting framework — it applies far beyond coding.
- Rich tool ecosystems like MCP and Skills allow agents to reach into nearly any system.
- Many “non‑coding” tasks can be reframed as coding problems, then solved via scripts.
- Stronger base models make the same scaffolds dramatically more capable.
So the next time you see an agent doing something “non‑coding,” don’t be too surprised. It may just be using code — behind the scenes — to solve problems you didn’t expect it to handle.
From a higher vantage point, the generalization of agent scaffolding stems from the generality of automation itself. And automation is exactly what computers are best at.
References
[1] Chain‑of‑Thought Prompting Elicits Reasoning in Large Language Models (https://arxiv.org/abs/2201.11903)
[2] ReAct: Synergizing Reasoning and Acting in Language Models (https://arxiv.org/abs/2210.03629)
[3] ReAct: The Architecture That Unifies Agentic Reasoning (https://aakashsharan.com/react-agent-architecture/)
[4] SWE‑Agent: Agent‑Computer Interfaces Enable Automated Software Engineering (https://swe-agent.github.io/)
[5] Claude Code Documentation (https://docs.anthropic.com/en/docs/claude-code/overview)
[6] OpenCode: The Open‑Source AI Coding Agent (https://opencode.ai/)
[7] OpenDev: Building AI Coding Agents for the Terminal (https://arxiv.org/html/2603.05344v1)
[8] Morph: We Tested 15 AI Coding Agents (2026) (https://morphllm.com/ai-coding-agent)
[9] Bosio Digital: The Agent Arms Race (https://bosio.digital/articles/agent-arms-race-openai-anthropic-google)
[10] Reddit: I Built an OpenClaw‑Like Agent with Claude Code, Cron, and App Integrations (https://www.reddit.com/r/ClaudeAI/comments/1r78tuq/)
[11] Zylos Research: Computer Use and GUI Agents in 2026 (https://zylos.ai/research/2026-02-08-computer-use-gui-agents)