未来的软件,会不会只是一堆纯文本?
未来的软件,会不会只是一堆纯文本?
封面来源:CLI-Anything
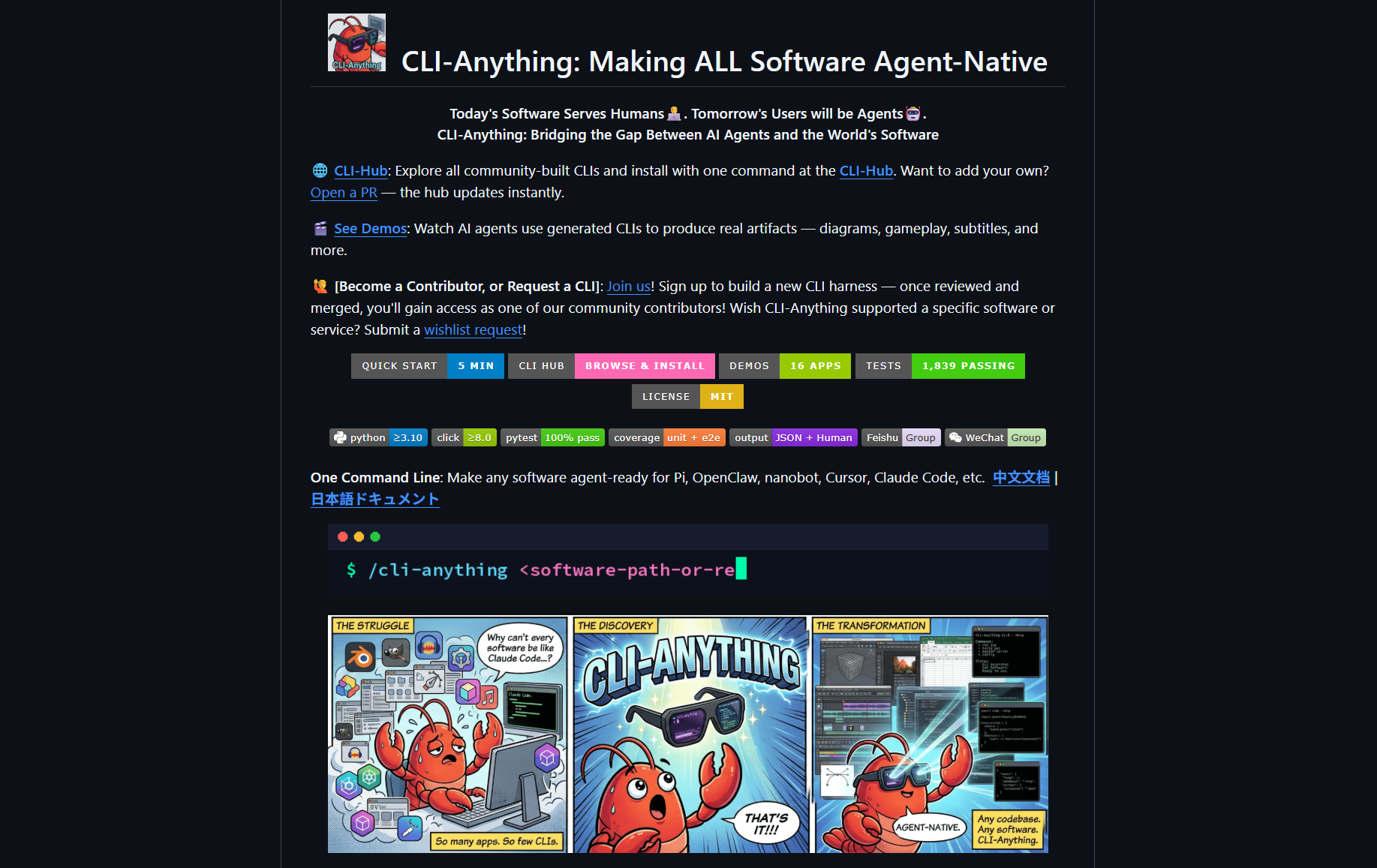
最近,一个叫 CLI-Anything 的开源项目在开发者圈子和学术圈里都传开了。这个项目来自香港大学(HKUDS)黄超老师课题组,在 GitHub 上快速积累了大量关注,在我写这篇文章的时候已经有 29k star 了。
 CLI-Anything
图片来源:CLI-Anything Github Repository
CLI-Anything
图片来源:CLI-Anything Github Repository
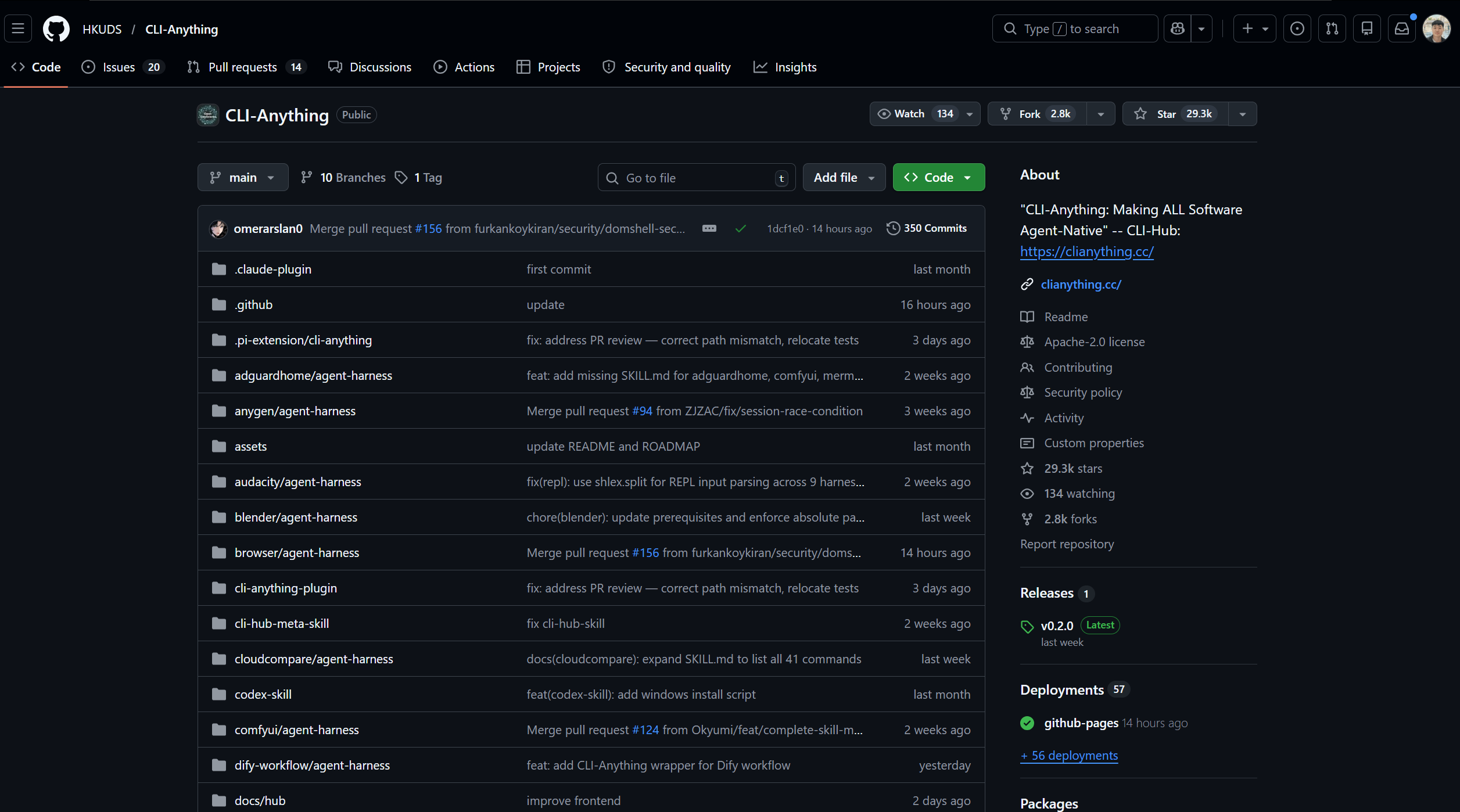
当你打开 CLI-Anything 的仓库(核心代码在 https://github.com/HKUDS/CLI-Anything/tree/main/cli-anything-plugin),会发现:这个项目里几乎没有什么代码,主要是 .md 文件——也就是纯文本的 Markdown 文档。这些文档用自然语言描述了把目标软件“CLI化”的SOP,以及各种 CLI 工具的使用方式和工作流程,然后由你本地的 coding agent(比如 Claude Code)来”理解并执行”。换句话说,coding agent 变成了这个软件的”运行时”和”驱动程序”。
这让我想到一个问题:未来的软件,会不会只是一堆纯文本?
CLI-Anything 做了什么?
先简单说说这个项目本身。
传统的 CLI 工具,比如 ffmpeg、git、rsync,各有各的参数风格,各有各的文档,学习曲线陡峭。使用者往往需要花大量时间去记命令、翻 man page,或者反复 Google。
CLI-Anything 的思路很不一样。它提供的不是一个新的 CLI 工具,而是一套自然语言描述的”使用指南”,由你的本地 coding agent 来读懂并执行。你只需要告诉 agent 你想做什么,agent 会参考这些 .md 文件,自动调用合适的 CLI 命令、组合参数、处理输出。
这是一个很有前瞻性的,同时也很成功的开源项目。但本文我不会谈太多项目本身的内容,主要是想聊聊以 CLI-Anything 为代表的这种软件形态。
一种新的软件范式?
我们习惯的软件范式是这样的:
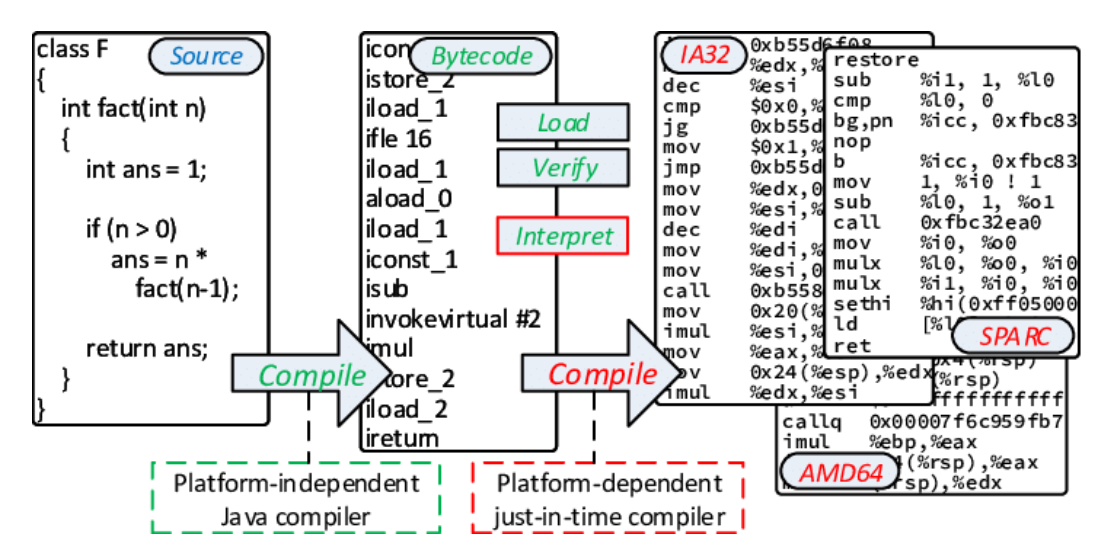
人类写代码 → 编译成二进制 → 机器执行
 Compile Process
图片来源:https://www.researchgate.net/
Compile Process
图片来源:https://www.researchgate.net/
而 CLI-Anything 代表的是另一种可能:
人类写自然语言 → coding agent 理解并执行
这两者的区别,表面上看只是”中间层不一样”,但背后的含义差很多。
在传统范式里,软件的”内容”是机器码或字节码。它是为机器设计的,人类读起来费劲,甚至根本读不了。加密和保护软件,靠的是让人类更难理解这些代码。
在新范式里,软件的”内容”是自然语言。它本质上是人类写给人类看的,顺便也能被 agent 执行。这意味着:软件第一次可以同时对人类和机器都”可读”。
这个想法能走多远?
想象一个更极端的场景。
你去软件商店,下载一款”文字处理工具”。安装完之后,你的磁盘里多了几个 .md 文件(或者这些文本被加密,人类不可读),里面用自然语言描述了这个软件能做什么、怎么做。然后,你的本地 coding agent 读取这些文件,并作为”驱动程序”,根据你的自然语言指令,实时生成并执行对应的操作。
没有二进制文件,没有可执行程序,只有文本和 agent。
这个想法乍看有些荒诞,但仔细想想,它其实触碰了软件的一个本质问题:软件到底是什么?
软件不是二进制本身,二进制只是一种”翻译结果”。软件的核心是意图——一套描述”做什么、怎么做”的逻辑。二进制是把这套逻辑翻译成机器能读懂的形式;而自然语言,是把这套逻辑表达成人类能读懂的形式。如果 agent 强大到足以”理解”自然语言并”执行”,那翻译成二进制这一步,就不是必须的了。
不得不考虑的现实障碍
当然,这里面有很多技术和非技术层面的问题需要认真对待,不能只说愿景。
可靠性问题。 Agent 理解自然语言不是百分之百精确的。同一段文字,不同的 agent、不同的上下文,可能得出不同的理解。这和二进制执行的确定性是截然不同的。对于一些需要精确控制的场景(比如金融交易、手术机器人),这种不确定性目前还难以接受。
性能问题。 每次”运行”都要让 agent 理解并生成执行计划,远比直接执行二进制慢得多。这在很多场景下是可以接受的,但并非所有场景。
安全和版权问题。 如果软件就是文本,那复制和传播会极其容易。现有的软件版权保护逻辑建立在”二进制难以复现源意图”的基础上,纯文本软件会让这套逻辑瓦解。加密文本是个思路(就像前面说的”安装加密文本”),但这又带来密钥管理的新问题。
标准化问题。 今天的 CLI-Anything 依赖的是 claude code 这个具体的 agent。不同 agent 对同一段文本的理解可能不同。如果未来真的要走”文本即软件”这条路,需要某种 agent 能力的标准化,或者某种能让不同 agent 对同一文本产生一致理解的机制。
但这个方向是真实的
尽管有这些障碍,我认为 CLI-Anything 揭示的方向是真实存在的,而且已经在发生。
它不是第一个这样做的。类似的项目和实践已经越来越多,都在以各自的方式印证这个方向。
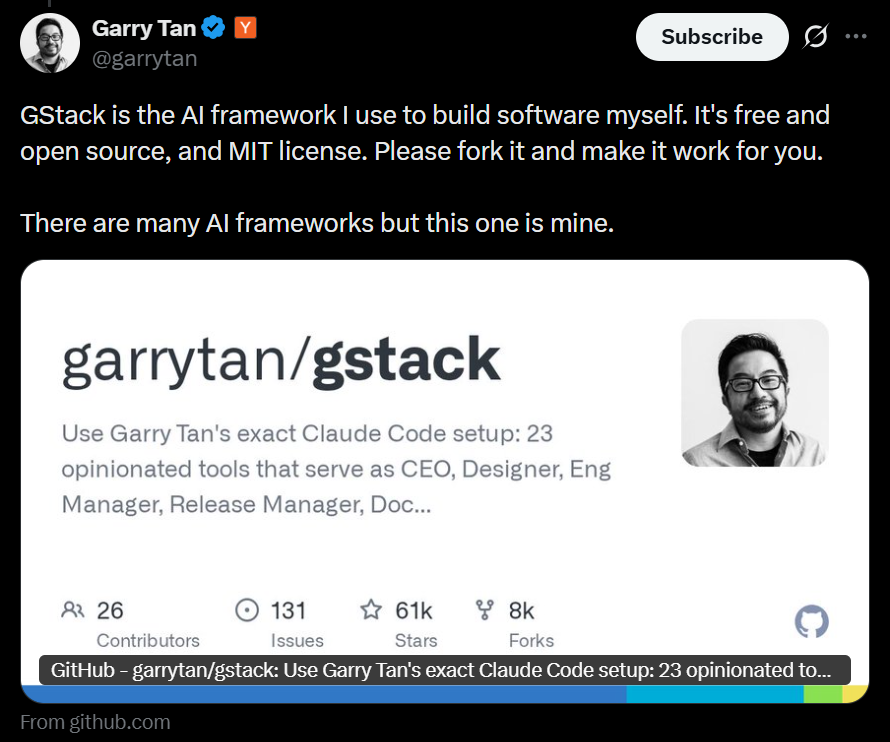
Gstack,Y Combinator CEO Garry Tan 发布的开源框架,在 GitHub 上迅速获得了大量关注[4]。它的核心同样是一组 Markdown 文件,这些文件定义了一套”角色技能”——CEO、工程负责人、QA 负责人、发布工程师……每个角色都有对应的职责描述和行为规范,全部用自然语言写成。当你在 Claude Code 里触发对应的斜杠命令(如 /plan-ceo-review、/qa、/ship),agent 就会读取对应的 Markdown 文件,”扮演”那个角色并执行相应的开发阶段工作。整个框架几乎没有可执行代码,却能把一个本地 coding agent 变成一支虚拟的开发团队。
 图片来源:https://x.com/garrytan/status/2038391669679362079
图片来源:https://x.com/garrytan/status/2038391669679362079
CLAUDE.md 和 PROJECT.md 本身也是这个范式的体现。你在越来越多的 GitHub 仓库里看到这些文件——它们用自然语言描述”这个项目是什么、用什么技术栈、开发时要遵守哪些规范”,然后让 coding agent 在每次启动时读取并内化,作为接下来所有行动的基础。Anthropic 官方对 CLAUDE.md 的支持和推广,某种程度上已经是在把”文本作为软件配置”纳入正式规范[2]。
CLI-Anything 本身的 SKILL.md 机制也值得一提。它引入了 SKILL.md 文件格式,让每一个 CLI 工具封装成 agent 可发现、可安装的”技能包”——agent 不需要人工介入,可以自主找到并安装新工具。这已经不只是”文本描述功能”,而是一套以文本为基础、agent 可自主扩展的工具生态[5]。
这和早年的”声明式编程”思想有某种相似之处——你描述”要什么”,而不是”怎么做”,让底层系统去决定执行细节。只不过现在的”底层系统”变成了 coding agent,”声明语言”变成了自然语言。
而且,随着 agent 能力越来越强,这条路会走得越来越深。现在 CLI-Anything 还只是”辅助 CLI 工具的自然语言指南”,但边界不会停在这里。
我真正想说的
我不是在预测”二进制代码会消失”。传统软件范式有它的优势和不可替代性,至少在相当长的时间内,两种范式会并行存在。
我想说的是:软件的定义正在变得比以前更宽。
从前,”软件”必须是可执行的机器码;后来,解释型语言让”软件”变成了人类可读的脚本;现在,agent 让”软件”可以是自然语言文本。每一次变化,都是让”表达意图”的门槛更低,让更多人能参与到”创造软件”这件事里来。
今后,我们运行安装包以后,安装包安装的可能就是一堆结构化的文本和一个coding agent驱动程序,自然语言描述变成了软件的护城河。
 图片来源:How to make an installer to your program
图片来源:How to make an installer to your program
CLI-Anything 只是一个小小的样本,但它让我真实地感受到:以 agent 为运行时的”纯文本软件”,不只是一个脑洞,它在某些场景下已经在工作了。
接下来会走多远,很值得持续观察。
参考来源:
[1] HKUDS/CLI-Anything GitHub 仓库 (https://github.com/HKUDS/CLI-Anything)
[2] Anthropic Claude Code 官方文档:CLAUDE.md 与 memory 机制 (https://docs.anthropic.com/en/docs/claude-code/memory)
[3] 声明式编程 - Wikipedia (https://en.wikipedia.org/wiki/Declarative_programming)
[4] Gstack GitHub 仓库(Garry Tan, Y Combinator CEO)(https://github.com/garrytan/gstack)
[5] CLI-Anything 文档:SKILL.md 机制与 CLI-Hub 生态 (https://github.com/HKUDS/CLI-Anything)