为什么 Claude Code 在大量非代码任务上也能表现出色?
为什么 Claude Code 在大量非代码任务上也能表现出色?—— 聊聊 Agent 脚手架的泛化性
封面来源:Claude Code Official Homepage
如果你是一名开发者,你大概率听说过 Claude Code、OpenCode,或者更早的 SWE-Agent。这些工具最初是为了解决代码生成问题而生的——帮我们修 Bug、写代码、跑测试。但你有没有想过一个问题:为什么它们不仅能写代码,还能在很多看似与代码无关的任务上表现出色?
比如,让 Claude Code 帮你整理一下桌面文件、批量重命名一批照片、或者自动填个表格——它居然也能干得不错。
这里面的功劳,固然要归功于底层模型的强大能力。但除此之外,还有一个经常被忽视的重要因素:Agent 脚手架(Agent Scaffolding)。
今天这篇文章,就来好好聊聊这个话题。
首先,澄清几个容易混淆的概念
在深入讨论之前,我觉得有必要先区分几个概念,因为这是非行业内的人经常容易搞混的。
LLM(Large Language Model,大语言模型):这是最底层的”大脑”,比如 GPT-5、Claude 4.5 Sonnet、DeepSeek-V3 等等。你给它们输入文字,它们输出文字——仅此而已(经典 LLM 一次输出一个token)。LLM 本身不会执行任何操作,它只是一个文本生成器。
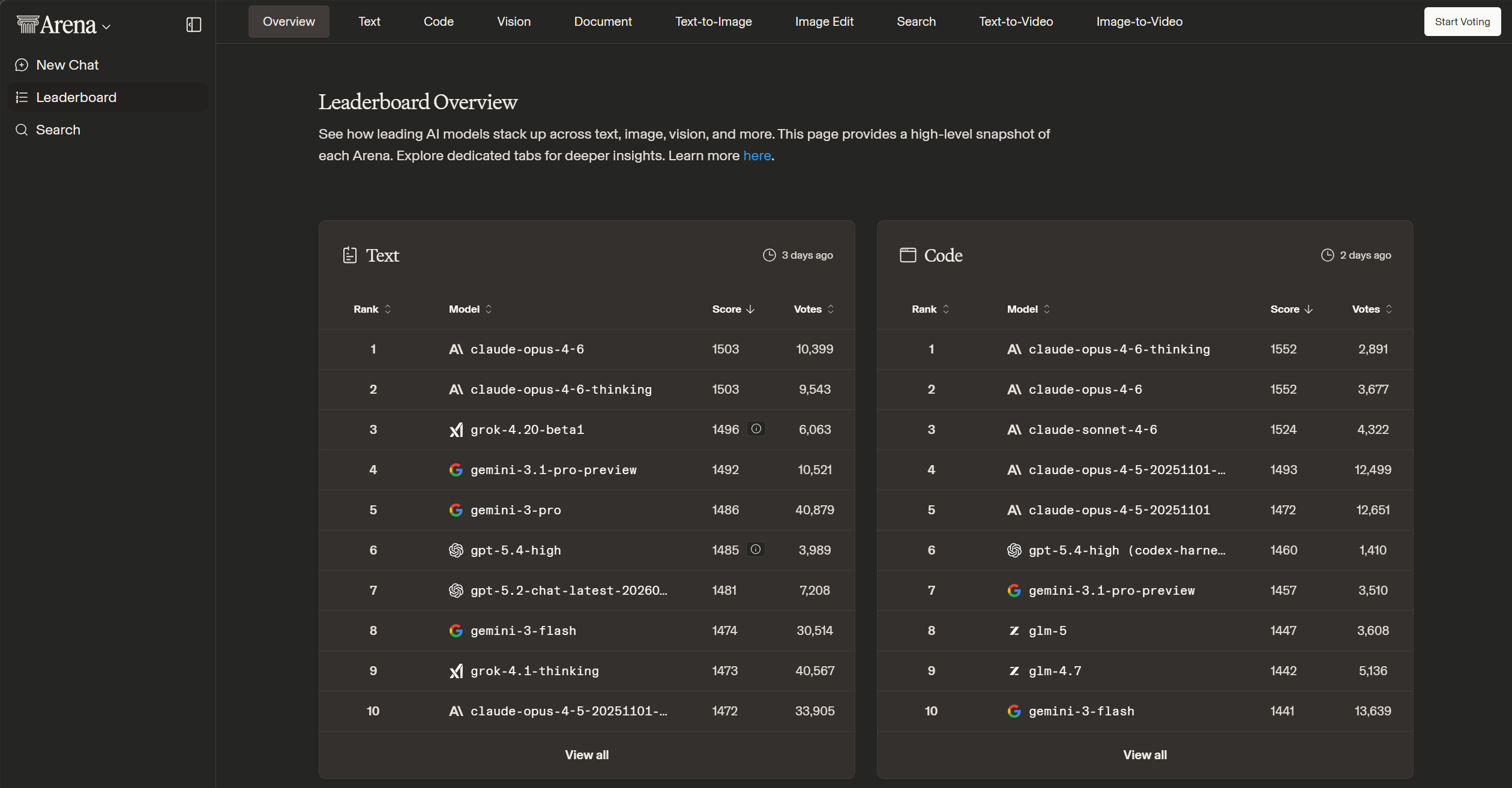 一个知名的 LLM 能力排行榜
图片来源:LM Arena
一个知名的 LLM 能力排行榜
图片来源:LM Arena
LLM Agent(LLM 智能体):是在 LLM 外面再包了一层”身体”和”感官”。它会把 LLM 当成大脑,然后额外接上一堆”手脚”——比如”读写文件”“执行命令行”“调用 HTTP API”“操作浏览器”等工具。Agent 做的事情,大致可以概括为:
- 把用户的自然语言需求翻译成一系列可以执行的动作计划
- 在每一步中调用 LLM 来思考,然后调用工具来行动
Claude Code 就是一个典型的 LLM Agent:它内部有多个子 Agent,有的负责读代码,有的负责改代码,有的负责跑测试,底层都在调用某个 LLM,但整体对外呈现的是一个”能自己动手写代码”的智能体。
 另一个知名的能力排行榜,但这次评测的对象是智能体。该评估框架评测的是智能体使用终端命令的能力。终端(shell命令)是智能体操作计算机的最主要形式。
图片来源:terminal-bench
另一个知名的能力排行榜,但这次评测的对象是智能体。该评估框架评测的是智能体使用终端命令的能力。终端(shell命令)是智能体操作计算机的最主要形式。
图片来源:terminal-bench
LLM 应用(LLM Application):是在 Agent 之上,更上一层的”产品形态”。它不只是一个 Agent,而是一个完整的应用系统,包含:
- 前端交互界面(网页、桌面 App、IDE 插件、手机 App 等)
- 后端服务(鉴权、日志、计费、权限控制、组织管理等等)
- 一个或多个 LLM / LLM Agent 作为”内核能力”
举个例子: - ChatGPT 是一个基于 LLM 的应用,它背后可能包含多个模型、多个 Agent、多个工具调用系统,但对用户来说只有一个产品入口。
- 你现在用的某个 AI 编程工具,本质也是一个 LLM 应用,只不过它在 IDE 里长出来。
所以,“LLM” 是一块芯片,”LLM Agent” 是一台可以自己动的机器,而 “LLM 应用” 是把这台机器装进一个完整的产品里并卖给用户。
科技公司、模型训练方、模型提供商(含 API 中转站):这三者经常被混为一谈,其实角色各不相同,搞清区别能让你在选型、付费、合规时少走弯路。
-
科技公司(品牌方)
负责融资、产品、市场,不一定自己训练模型。
海外如 Anthropic、OpenAI、Google;
国内如月之暗面(Moonshot AI)、MiniMax、智谱 AI、百川智能。 - 模型训练方
真正投入算力、数据、算法去训练底座模型的团队。
例如:- Claude 4.5/4 系列由 Anthropic 训练;
- GPT-5/o1 由 OpenAI 训练;
- Kimi 2.5 由月之暗面训练;
- GLM-5 由智谱 AI 训练;
- Baichuan 3 由百川智能训练。
注意:训练方有时会把模型“卖”或“授权”给同集团内的科技公司,也可能对外提供 API。
- 模型提供商(含官方直售与 API 中转站)
把训练好的模型封装成可调用的 API、SaaS 或私有化包,向开发者收费。- 官方直售:OpenAI API、Anthropic API、Google Vertex AI、阿里云“百炼”平台、腾讯云“混元”API、百度千帆大模型平台、月之暗面开放平台。
- API 中转站:国内常见的有 硅基流动(SiliconFlow)、Together.ai、云托管的 OneAPI、Cloudflare AI Gateway、阿里“魔搭”GPU 托管等。它们把官方(或开源)模型做一层反向代理,统一鉴权、计费、限速,方便国内开发者直接调用,但价格、日志留存、合规责任都与官方不同。
举例: - 你在 SiliconFlow 上调用 deepseek-ai/DeepSeek-V3,模型训练方是深度求索,SiliconFlow 只是提供商;
- 你在百度千帆调用 ERNIE-4.0,训练方是百度,千帆是官方提供商;
- 你在腾讯云调用混元大模型,训练方是腾讯,提供商也是腾讯自己。
Agent 脚手架简史:从提示词到智能体
要理解今天的 Agent 脚手架为什么有如此强的泛化性,我们需要回顾一下它的发展历程。
1. Prompt Engineering(提示词工程):最初的尝试
最早的 LLM 应用其实很简单——就是写好提示词(Prompt),让模型输出你想要的结果。
比如你说:”请用 Python 写一个快速排序函数。”模型就给你写一段代码。
这种方式简单直接,但有一个致命问题:模型太”懒”了。你让它写代码,它就只写代码;你让它总结文章,它就只总结文章。它不会主动去查资料、不会验证自己的答案对不对、更不会在你给出一个模糊指令时主动追问。
2. CoT(Chain-of-Thought,思维链):让模型学会”思考”
2022 年,Google 的研究人员提出了 Chain-of-Thought(思维链)提示技术[1]。核心思想很简单:让模型把思考过程写出来,而不是直接给出答案。
举个例子:
- 没有 CoT:问 “小明有 5 个苹果,小红给他 3 个,小明现在有几个?” → 模型直接输出 “8 个”
- 有 CoT:模型会写出 “5 + 3 = 8,所以小明有 8 个苹果”
这个变化看起来微小,实际上意义重大。CoT 让模型学会了”分步思考”,大大提升了它在数学、逻辑推理等复杂任务上的表现[1]。
 图片来源:Kojima et al., Large Language Models are Zero-Shot Reasoners
图片来源:Kojima et al., Large Language Models are Zero-Shot Reasoners
但 CoT 依然有一个局限:它只解决了”想”的问题,没有解决”做”的问题。模型可以在脑海里推理,但它无法主动去验证自己的答案,也无法获取外部信息。
3. ReAct(Reasoning + Acting):让模型既会想又会做
2023 年,Yao 等人发表了著名的 ReAct 论文[2],提出了一个关键的洞察:光让模型”想”是不够的,还要让它能”做”。
ReAct 的核心框架是”Thought → Action → Observation”(思考 → 行动 → 观察)的循环:
- Thought(思考):模型分析当前情况,制定下一步计划
- Action(行动):模型执行一个动作,比如搜索信息、调用 API、读取文件
- Observation(观察):模型获取行动的结果,用它来更新自己的理解
- 循环往复,直到任务完成
这个设计太关键了。正如一位研究者所说的:”CoT 给了模型’思考’的能力,工具调用给了模型’行动’的能力,但它们缺乏一个把两者结合起来的机制。ReAct 补上了这块拼图。”[3]
更有趣的是,研究表明 ReAct 还能显著减少”幻觉”(Hallucination)。在 HotpotQA 数据集上,CoT 产生的错误陈述超过了一半,而 ReAct 把这个数字降到了接近零[3]。
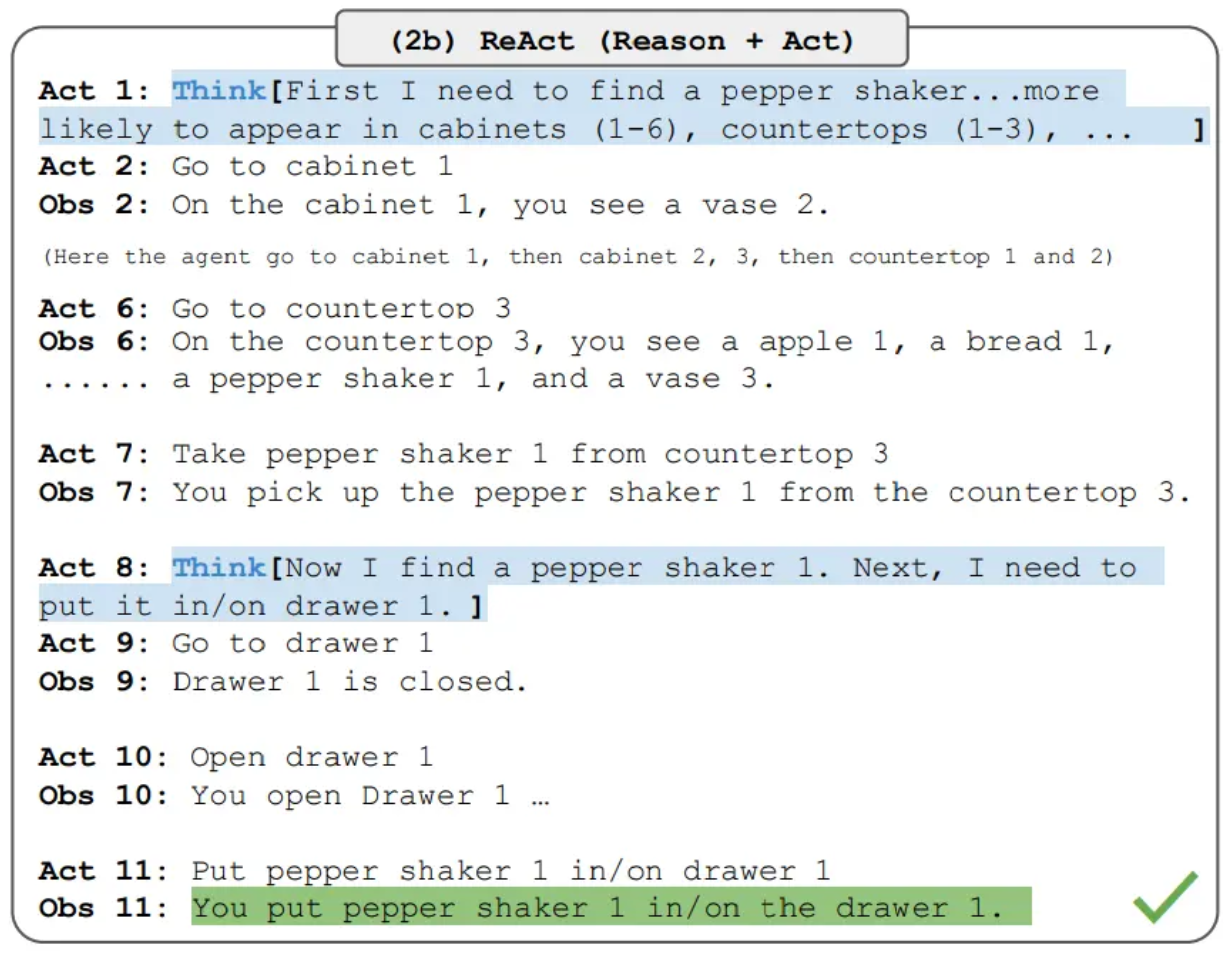 图片来源:Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models
图片来源:Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models
4. SWE-Agent:代码场景的专精进化
在 ReAct 的基础上,针对代码场景的专用 Agent 开始涌现。SWE-Agent 是其中的典型代表[4]。
SWE-Agent 的核心创新在于它的CodeAct Agent设计:
- File Agent:负责读取和理解代码文件
- Edit Agent:负责修改代码
- bash Agent:负责执行命令行操作
- Browser Agent(可选):负责浏览器操作
每个子 Agent 都有明确的职责,通过一个统一的”调度器”来协调工作。这种架构让 SWE-Agent 能够处理复杂的、多步骤的软件工程任务。
后来,SWE-Agent 的设计理念被更广泛地采用,发展成为今天我们看到的各种 Terminal-Native Agent。
5. Claude Code、OpenCode:终端原生 Agent 的崛起
时间来到 2024-2025 年,Terminal-Native Agent(终端原生 Agent)开始崛起。
Claude Code 是 Anthropic 推出的终端原生 AI 编程助手。它有两个核心模式[5]:
- Terminal 模式:直接交互式开发
- Gateway 模式:7×24 小时运行,监听各种消息源(WhatsApp、Telegram、Slack 等)
Claude Code 的一个关键创新是子 Agent(Subagent)架构。它可以同时运行多个并行的 AI Agent,每个 Agent 有自己的上下文窗口、模型选择、工具访问权限和权限控制。一个内置的 Explore Agent(运行 Haiku 模型)负责代码库搜索,而更复杂的工作则交给 Sonnet 或 Opus 模型[5]。
OpenCode 则是另一个值得关注的存在。作为开源项目,OpenCode 在 GitHub 上已经获得了超过 12 万颗星,超过了 Claude Code[6]。它的核心理念是“Provider Agnostic”(模型无关)——支持 75+ 个模型提供商,包括 Claude、GPT、Gemini,以及各种本地模型[6]。
揭开 Claude Code 的工作原理
由于 Claude Code 是闭源的,我们无法直接看到它的源码。但我们可以从它的”近亲”——开源的 SWE-Agent 和 OpenDev——来理解这类 Agent 脚手架的工作原理[4][7]。
核心工作流程
以 SWE-Agent 为例,它的工作流程大致如下[4]:
第一步:理解任务 Agent 接收用户的自然语言指令(比如”帮我修复这个 Bug”),然后分析需要哪些步骤来完成这个任务。
第二步:规划路径 Agent 会制定一个执行计划:先读哪个文件、再改哪里、最后怎么验证。
第三步:执行动作 Agent 开始执行计划中的动作。它可以:
- 读取文件内容
- 搜索代码
- 编辑代码
- 执行命令行
- 运行测试
第四步:观察反馈 每次执行后,Agent 都会获取执行结果(命令输出、测试结果等),并用这些信息来更新自己的理解。
第五步:迭代优化 如果发现当前方案不行,Agent 会主动调整计划,尝试新的方法。
关键组件
一个完整的 Agent 脚手架通常包含以下几个关键组件[7]:
- System Prompt(系统提示词):定义 Agent 的角色、能力边界和行为规范
- Tool Schemas(工具定义):告诉 Agent 有哪些工具可用,每个工具的用途和调用方式
- Subagent Registry(子 Agent 注册表):管理多个子 Agent 的配置和权限
- Context Manager(上下文管理器):管理对话历史、文件内容、执行状态等
- Execution Harness(执行 harness):负责任务调度、工具分发、安全防护
这就是为什么 MorphLLM 的一位分析师会说:”我们测试了 15 个 AI 编程 Agent,发现脚手架(Scaffolding)比模型本身更重要。Augment、Cursor 和 Claude Code 用的都是 Opus 4.5,但在 SWE-bench 上相差 17 个问题。”[8]
Agent 脚手架为什么有泛化性?
看完上面的“核心工作流程”,是不是感觉也就这回事儿了…
没有太多复杂的trick,整体设计非常简洁朴素。
现在来到本文的核心问题:为什么这些为代码任务设计的 Agent 脚手架,在大量非代码任务上也能表现出色?
我认为主要有以下几个原因。
1. ReAct 思想的普适性
首先,也是最根本的原因,是 ReAct 框架的普适性。
ReAct 的核心思想——”Thought → Action → Observation”的循环——其实是一个通用的解决问题的框架,它并不局限于任何特定领域。
无论你是要写代码,还是要整理文件,还是要从网上查资料并整理成报告,核心过程都大差不差:
- 理解任务
- 制定计划
- 执行动作
- 获取反馈
- 迭代优化
这就是为什么 ReAct 可以在从 HotpotQA(知识问答)到 ALFWorld(文字游戏)的各种任务上都取得不错的效果[2]。
2. 工具生态的丰富:MCP 与 Skill
其次,工具生态的丰富极大地扩展了 Agent 的能力边界。
MCP(Model Context Protocol) 是 Anthropic 提出的一个开放标准,旨在让 AI Agent 能够与各种外部服务和工具无缝连接[9]。截至 2026 年初,MCP 已经有了超过 10,000 个服务器,SDK 月下载量达到 9700 万次[9]。
这意味着什么?意味着现在的 Agent 不仅可以读写文件、执行命令,还可以:
- 连接 GitHub、Slack、Linear 等开发工具
- 操作数据库、调用 API
- 发送邮件、编辑日历
- 甚至控制智能家居设备
Skill 是另一个重要的概念。在 Claude Code 和 OpenCode 中,Skill 允许用户定义预定义的工作流[10]。比如,你可以定义一个”发送周报”的 Skill,包含”读取项目进度 → 生成报告 → 发送到指定邮箱”的一系列步骤。
 图片来源:Skillsmp官方网站
图片来源:Skillsmp官方网站
有了 MCP 和 Skill,Agent 脚手架实际上获得了一个可扩展的工具箱。它不仅可以处理代码任务,还可以处理各种”非典型”任务——只要你给它合适的工具。
3. 大多数问题都可以”建模”为代码问题
第三个原因可能有点反直觉,但我觉得非常关键:大多数看似非代码的问题,其实都可以转化为代码问题来解决。
举几个例子:
场景一:整理桌面文件 你让 Agent 帮你把桌面上的文件按类型分到不同文件夹。这看起来是个文件管理任务,但如果从”代码”的视角来看,整个过程可以被建模为:
- 用 Python 的
os、shutil库列出桌面目录、创建目标文件夹、批量移动文件 - 用正则表达式来匹配文件名模式(比如按照日期、项目名、版本号分组)
- 对于图片,还可以用
PIL或exifread读取 EXIF 信息,根据拍摄时间、设备类型等规则分类 换句话说,这个任务就是一段”读取目录 → 计算分类规则 → 移动重命名”的脚本。Agent 所做的,是先理解你的自然语言需求,再自动写出并执行这段脚本,而不是一张一张拖拽图标。
场景二:批量重命名照片 你让 Agent 把一批照片按日期重命名。这看起来是个图像处理任务,但可以被建模为:
- 用
exifread或类似库读取每张照片的拍摄日期、时间、相机型号等元数据 - 用 Python 的
datetime库把这些时间格式化成统一的文件名,比如2026-02-23_旅行_001.jpg - 用
os.rename在文件系统里批量重命名 本质上,这是一个”解析元数据 → 生成新名字 → 执行重命名”的纯代码流程。Agent 只是在背后帮你把这个小工具写好并运行而已。
场景三:自动填表格 你让 Agent 帮你把 Excel 里的数据填到某个网页表单中。这看起来是个”GUI 操作”任务,但如果允许走 HTTP/浏览器自动化路线,完全可以被写成:
- 用
openpyxl或pandas读取 Excel 中的结构化数据 - 根据表单字段定义,把每一列映射成 JSON 或表单字段
- 用
requests直接提交 HTTP 请求,或者用selenium/Playwright 驱动浏览器自动填充并提交 从代码角度看,这是一个”读取结构化数据 → 做字段映射 → 发送请求”的标准 ETL(Extract-Transform-Load)流程。
场景四:生成每周工作周报 很多人会让 Agent 帮忙写一份周报,看起来像是”写作任务”。但如果你把需求拆开,会发现它完全可以被建模成代码:
- 先用脚本从 Git 提交记录、Issue/PR、日历事件、聊天记录(Slack/飞书)中拉取这一周的活动数据
- 用代码对这些数据做聚合和筛选(按项目归类、按优先级排序)
- 最后再调用 LLM 把这些结构化要点整理成一篇自然语言周报 在这个流程里,LLM 只是负责”润色”和”表达”,而真正的”信息收集和整理”部分,完全是可以用代码可靠完成的。
场景五:清洗一份”脏”的 CSV 数据 你让 Agent 帮你把一份 CSV 里的脏数据清洗干净,看起来是”数据分析”任务,但实际上可以被建模为:
- 用
pandas读取 CSV - 写一套规则:比如去掉空行、填充缺失值、统一时间格式、规范枚举值(”Y/Yes/True” 统一成
True) - 对异常值进行检测和修正,比如用统计方法找出离群点、自动标记出来供你审阅 最终,Agent 交付给你的是一个经过清洗的 CSV 文件,以及一段可以复用的清洗脚本。
发现规律了吗?代码是天然的”自动化语言”。无论是文件操作、数据处理、网络请求,还是系统管理——都可以用代码来完成。很多你以为”Agent 在帮你手工操作”的场景,本质上都是”Agent 在帮你写脚本 + 跑脚本”。
而 Agent 脚手架,恰恰就是那个能让 AI “写代码、做自动化”的框架。所以,当你觉得 Agent 在做”非代码任务”时,它可能正在悄悄写代码呢。
4. 底层模型的通用能力
当然,我们不能忽视底层模型的贡献。
2025 年是 LLM 能力爆发的一年。OpenAI 的 o1/o3 系列、Anthropic 的 Claude 4 系列、Google 的 Gemini 2.5,都展示了惊人的推理和规划能力[11]。
更重要的是,这些模型的通用能力越来越强。一个训练良好的模型,不仅能写代码,还能:
- 理解自然语言指令
- 进行多步骤推理
- 调用各种工具
- 从反馈中学习和调整
模型能力的提升,相当于给 Agent 脚手架提供了一个更聪明的”大脑”。同一个脚手架,用更强的模型,结果可能天差地别。
Agent 脚手架会有革命性的改变吗?
说了这么多,你可能会问:Agent 脚手架以后会有革命性的改变吗?
我持审慎乐观的态度。
可能的发展方向
多模态融合:未来的 Agent 可能会更好地整合视觉、听觉等多种感知能力,处理更复杂的信息。
更自主的规划:目前的 Agent 大多还是”反应式”的——你给指令,它执行。未来的 Agent 可能会更主动,能够自己制定长期计划并执行。
更好的记忆机制:现在的 Agent 在长对话中经常会”遗忘”之前的上下文。未来的 Agent 可能有更强大的记忆机制,能够在更长的时间跨度内保持一致性。
挑战与限制
但与此同时,也有一些根本性的挑战需要面对:
执行的不确定性:现实世界充满意外。Agent 执行一个动作,結果可能和预期完全不同。如何让 Agent 能够稳健地处理各种异常情况,是一个巨大的挑战。
安全与权限:让 Agent 拥有执行各种操作的权限,本身就有安全风险。如何在能力和安全之间取得平衡,是一个需要持续思考的问题。
评估的困难:如何评估一个 Agent 的能力?现有的 Benchmark(如 SWE-bench、Terminal-Bench)都有各自的局限性[8]。
总结
回到最初的问题:为什么 Claude Code 在大量非代码任务上也能表现出色?
答案已经很清楚了:
- ReAct 框架的普适性:它不仅仅适用于代码,而是一个通用的”感知-思考-行动”循环
- 工具生态的丰富:MCP 和 Skill 让 Agent 可以连接到几乎任何服务
- 代码作为通用接口:大多数自动化任务,最终都可以用代码来实现
- 底层模型的通用能力:更强的模型,让同样的脚手架发挥更大的作用
所以,下次当你看到 Agent 在做一些”非代码”的事情时,不要太惊讶。它可能只是在用代码的方式,解决一个你原本以为它解决不了的问题。
从一个较高的视角看,Agent 脚手架的泛化性,本质上来自于“自动化”这个行为的通用性。而自动化,正是计算机最擅长的东西。
参考来源:
[1] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (https://arxiv.org/abs/2201.11903)
[2] ReAct: Synergizing Reasoning and Acting in Language Models (https://arxiv.org/abs/2210.03629)
[3] ReAct: The Architecture That Unifies Agentic Reasoning (https://aakashsharan.com/react-agent-architecture/)
[4] SWE-Agent: Agent Scaffolding for Autonomous Software Engineering (https://swe-agent.github.io/)
[5] Claude Code Documentation (https://docs.anthropic.com/en/docs/claude-code/overview)
[6] OpenCode: Open-Source AI Coding Agent (https://opencode.ai/)
[7] OpenDev: Building AI Coding Agents for the Terminal (https://arxiv.org/html/2603.05344v1)
[8] MorphLLM: We Tested 15 AI Coding Agents (2026) (https://morphllm.com/ai-coding-agent)
[9] Bosio Digital: The Agent Arms Race (https://bosio.digital/articles/agent-arms-race-openai-anthropic-google)
[10] Reddit: I built an OpenClaw-like agent with Claude Code, Cron, and App Integrations (https://www.reddit.com/r/ClaudeAI/comments/1r78tuq/)
[11] Zylos Research: Computer Use and GUI Agents in 2026 (https://zylos.ai/research/2026-02-08-computer-use-gui-agents)